Introduction
I feel like I've over extended on leetcode, and severely under extended on system design. Hence, I'll be documenting all the most relevant system design concepts I've come across.
I feel like I've over extended on leetcode, and severely under extended on system design. Hence, I'll be documenting all the most relevant system design concepts I've come across.
What actually happens under the hood?
1. The browser takes the url (google.com) and sends it to the DNS server. The DNS server will do a look up and return the server's IP address.
2. The browser establishes a TCP connection with the server through a three-way handshake (SYN, SYN-ACK, ACK).
3. The browser sends an HTTP request to the server.
4. The server sends an HTTP response back to the browser (HTML, CSS, JavaScript).
5. The browser renders the page using the response!
There are two types of databases: relational and non-relational.
Relational databases (SQL databases) are used to store data in table and rows, which you can perform JOIN operations on via SQL. Common ones include MySQL, PostgreSQL, and SQLite.
Non-relational databases (NoSQL databases) will store data in a key-value pair, column storage, graph storage, or document storage. Common ones include MongoDB, Cassandra, and Redis.
When do I use which?
Non-relational databases are better when
Dealing with massive amounts of data
Low-latency is required
No Relational data is required
When only need to serialize and deserialize data
Otherwise use a relational database.
There are two main types of scaling, vertical and horizontal.
Vertical scaling ("scape up") means adding more power (CPU, RAM) to your server.
Horizontal scaling ("scale out") means adding more servers to your server pool.
When do I use which?
Vertical scaling is better with low traffic, since it's simple. But the cons are that there are limits to how much power you can add. And if the server crashes, everything crashes (violates SPOF)
Horizontal scaling is better with high traffic, and large scale applications.
Consider your black-friday app running on 1 server. On black friday, you'll recieve so much traffic that it would reach the web server's load limit. User's will start to experience slower responsiveness and eventually, the server will crash.
A load balancer is used for this reason, to distribute traffic evenly across multiple servers.
The app will connect to a load balancer via the server's IP address. Then the load balance will connect to each server via a private IP address.
This allows the load balancer to identify and redirect traffic to the appropriate server.
In the same way having multiple servers prevents SPOF. We use database replication (multiple databases) to prevent data loss.
This is modelled via the master-slave relationship. The master database (only writes) and the slave database (only reads) replicate off the master database.
App's typically have more reads than writes, hence # of slaves > # of masters.
Having slave databases also allow for parallel reads, leading to better performance.
Sharding is another popular concept which partitions a large database into smaller independent pieces called shards, which allows you spread traffic across multiple shards so the database can handle more users / read+writes without one server being bottleneck'd.
Cache is a temporary storage area to store the result of expensive responses or frequently accessed data in-memory.
When the browser requests a resource, the web server checks if the cache has the resource. If it does, return it instantly. If not, the server will query the database for the response, add it to the cache, and return it.
Something to note is databases and cache's aren't always in sync i.e if the database undergoes UPDATE SQL query. One strategy is setting a expiration policy (TTL) on the cache, and resetting it.
If you reset it to often, you'll need to query the database more often. If you reset it to rarely, you'll risk serving stale data.
Sometimes, a cache can become full. If it does, there are a few strategies to evict and make space. Some include LFU (Least Frequently Used), and FIFO (First In First Out).
LRU is typically used by default. Temporal locality suggests that recently used items are likely to be used again soon.
LFU is better when some items are consistently popular over time.
CDN (Content Delivery Network) are geographcially disposed servers used to deliver static content (images, videos, CSS, JavaScript) to users.
There like a cache, but for static content.
Stateful servers remember client data from 1 request to the next.
Stateless servers keep no information about the client between requests.
The industry is moving towards stateless servers, as they are more scalable and easier to manage.
Message queues are durable components stored in memory that support async communication (think buffer for async requests).
The advantage comes in the decoupling, if the provider is unavailable, the consumer can still function and vice versa.
1KB -> 1MB -> 1GB -> 1TB -> 1PB
L1 cache: 0.5ns
L2 cache: 5ns
Mutex lock: 100ns
Main memory reference: 100ns
Disk seek: 10ms
Takeaways:
Memory is fast, but disk is slow
Perform loseless compression on data before sending it over the internet
Data centers are usually in different regions, so takes time to send data between them
High availability means for the system to be continiously operational for a long period of time.
Service level agreement (SLA) is an agreement between service provider and customer, defining level of uptime your service will deliver.
Consider twitter. 300 million monthly users. 50% use Twitter daily. Users post 2 posts / day. 10% tweets contain media. Data stored for 5 years.
Query per second (QPS):
Daily active users (DAU) = 300 million x 0.5 = 150 million
Tweets (QPS) = 150 million x 2 tweets / 24h / 3600s = ~3500
Peek QPS = 3500 x 2 = 7000
Average tweet size
tweet_id 64 bytes
text 140 bytes
media 1MB
Media storage: 150 million * 2 * 10% * 1MB = 30TB/day
5-year media storage = 30TB/day * 365days * 5 = 55PB
The general flow of a system design interview should follow this format:
1. Clarify the problem at hand
What is the feature set of this application?
What is the scope of the problem we're most interested in?
Is this a mobile app or web app?
2. List functional requirements (things users should be able to do)
Users should be able to post tweets
Users should be able to follow other users
Users should be able to see tweets from users they follow
3. List non-functional requirements (what your system should support)
System should scale to support 100M DAU's
System should be highly available, prioritizing availbility over consistency (CAP THEORM mention)
System should be low latency, should render <100ms
System should be read heavy
4. Design your database
We'll need a user, tweets, and follower table
What are the fields each table will store?
What are the primary and foreign keys?
5. Design your API endpoints
Will you use REST (most common), GraphQL (allows clients to query for exact data, used if have diverse clients with different needs), RPC (when performance is critical)
Define your endpoint names, request body, response body (these should cover your functional requirements)
6. Architecture diagrams
Drawing boxes and arrows to represent the different components of system and how they interact (client, server, databases, CDN, caching, load balancer)
Below is an example of an architecture diagram for designing twitter.
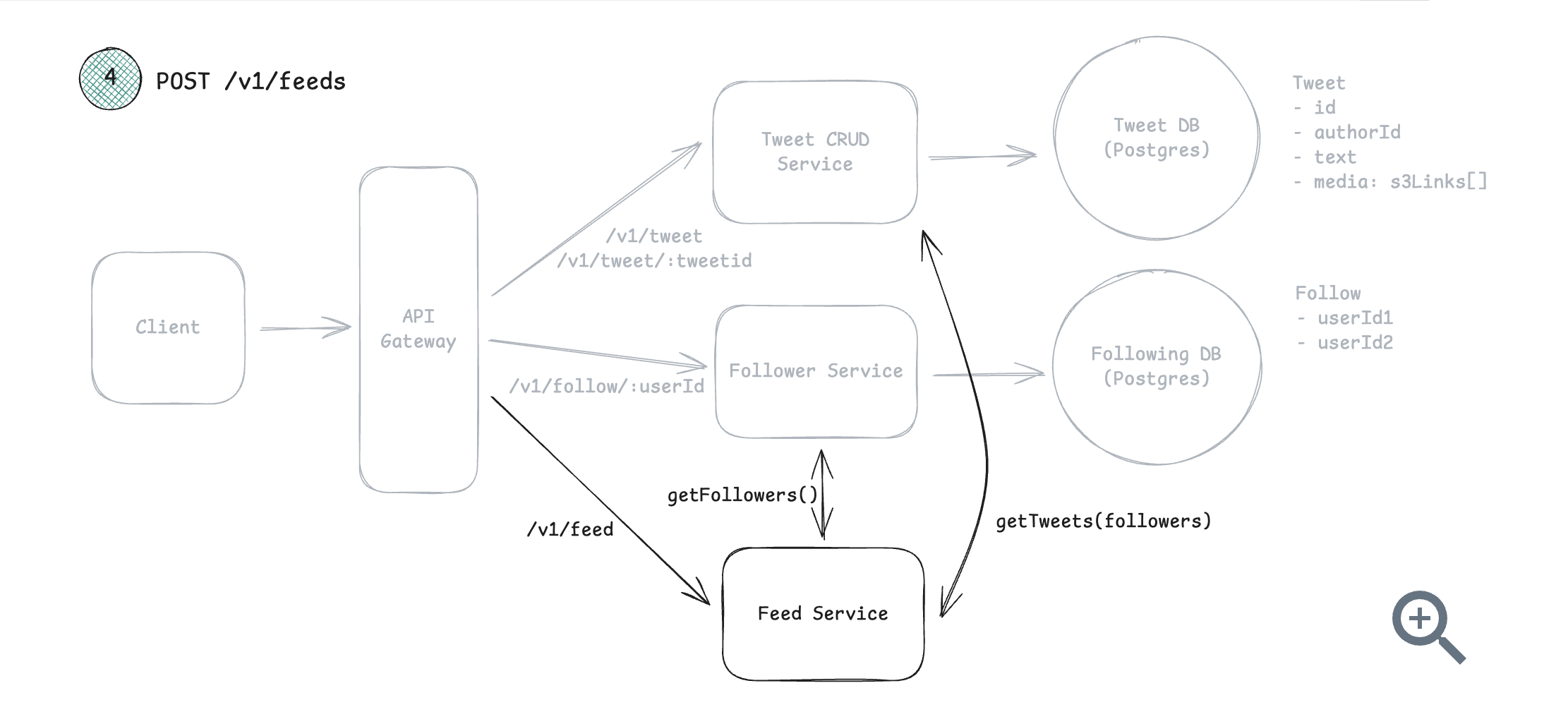
7. Deep dive
Ensure your solution satisfies your non-functional requirements (if 100M DAU, discuss horizontal scaling solutions)
Make those improvements suggested by the interviewer
Core Concepts
Networking is how services talk to each other, and what happens when they fail or get slow.
In system design interviews, the typical usuage is HTTP over TCP.
Websockets and server-side events (SSE uni-directional) come up when dealing with real-time updates.
However, typically, HTTP with polling could work alternatively to websockets in most cases.